

How Does Collaborative Filtering Work

This image shows an instance of predicting of the user's rating using collaborative filtering. At first, people rate different items (like videos, images, games). After that, the system is making predictions about user'south rating for an item, which the user hasn't rated however. These predictions are congenital upon the existing ratings of other users, who have similar ratings with the active user. For instance, in our case the system has made a prediction, that the active user won't similar the video.
Collaborative filtering (CF) is a technique used by recommender systems.[ane] Collaborative filtering has two senses, a narrow one and a more general i.[2]
In the newer, narrower sense, collaborative filtering is a method of making automatic predictions (filtering) almost the interests of a user by collecting preferences or taste information from many users (collaborating). The underlying supposition of the collaborative filtering approach is that if a person A has the same stance as a person B on an outcome, A is more likely to take B'south opinion on a different upshot than that of a randomly chosen person. For example, a collaborative filtering recommendation system for preferences in television receiver programming could make predictions virtually which television show a user should like given a partial list of that user's tastes (likes or dislikes).[3] Note that these predictions are specific to the user, but use information gleaned from many users. This differs from the simpler approach of giving an average (non-specific) score for each item of interest, for example based on its number of votes.
In the more general sense, collaborative filtering is the process of filtering for information or patterns using techniques involving collaboration among multiple agents, viewpoints, data sources, etc.[ii] Applications of collaborative filtering typically involve very large data sets. Collaborative filtering methods have been practical to many unlike kinds of data including: sensing and monitoring data, such as in mineral exploration, environmental sensing over big areas or multiple sensors; financial data, such every bit fiscal service institutions that integrate many fiscal sources; or in electronic commerce and spider web applications where the focus is on user information, etc. The remainder of this give-and-take focuses on collaborative filtering for user information, although some of the methods and approaches may apply to the other major applications as well.
Overview [edit]
The growth of the Internet has made it much more difficult to effectively extract useful data from all the available online information.[ according to whom? ] The overwhelming amount of information necessitates mechanisms for efficient information filtering.[ according to whom? ] Collaborative filtering is one of the techniques used for dealing with this problem.
The motivation for collaborative filtering comes from the idea that people often get the best recommendations from someone with tastes similar to themselves.[ citation needed ] Collaborative filtering encompasses techniques for matching people with like interests and making recommendations on this basis.
Collaborative filtering algorithms oft crave (i) users' active participation, (2) an easy style to represent users' interests, and (3) algorithms that are able to match people with similar interests.
Typically, the workflow of a collaborative filtering organization is:
- A user expresses his or her preferences by rating items (e.thou. books, movies, or music recordings) of the arrangement. These ratings can be viewed as an gauge representation of the user'due south interest in the corresponding domain.
- The system matches this user's ratings confronting other users' and finds the people with most "similar" tastes.
- With similar users, the system recommends items that the similar users have rated highly simply not however existence rated by this user (presumably the absence of rating is oft considered as the unfamiliarity of an item)
A key problem of collaborative filtering is how to combine and weight the preferences of user neighbors. Sometimes, users tin immediately rate the recommended items. Equally a result, the system gains an increasingly accurate representation of user preferences over time.
Methodology [edit]
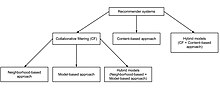
Collaborative Filtering in Recommender Systems
Collaborative filtering systems take many forms, but many common systems can exist reduced to two steps:
- Look for users who share the same rating patterns with the active user (the user whom the prediction is for).
- Use the ratings from those like-minded users institute in footstep ane to calculate a prediction for the active user
This falls under the category of user-based collaborative filtering. A specific application of this is the user-based Nearest Neighbour algorithm.
Alternatively, item-based collaborative filtering (users who bought 10 also bought y), proceeds in an particular-centric fashion:
- Build an item-particular matrix determining relationships between pairs of items
- Infer the tastes of the current user past examining the matrix and matching that user's information
Meet, for example, the Slope One item-based collaborative filtering family.
Another form of collaborative filtering can be based on implicit observations of normal user behavior (as opposed to the bogus behavior imposed by a rating task). These systems observe what a user has done together with what all users accept done (what music they take listened to, what items they have bought) and use that information to predict the user's behavior in the future, or to predict how a user might like to carry given the run a risk. These predictions then take to be filtered through business concern logic to determine how they might affect the actions of a business organisation. For case, it is not useful to offer to sell somebody a particular album of music if they already have demonstrated that they ain that music.
Relying on a scoring or rating system which is averaged beyond all users ignores specific demands of a user, and is particularly poor in tasks where there is big variation in involvement (every bit in the recommendation of music). Withal, there are other methods to combat information explosion, such as web search and data clustering.
Types [edit]
Memory-based [edit]
The retentivity-based approach uses user rating data to compute the similarity between users or items. Typical examples of this approach are neighbourhood-based CF and item-based/user-based top-Due north recommendations. For example, in user based approaches, the value of ratings user u gives to item i is calculated as an aggregation of some like users' rating of the detail:

where U denotes the gear up of summit Due north users that are most similar to user u who rated item i. Some examples of the assemblage part include:


where k is a normalizing cistron defined as , and


where is the boilerplate rating of user u for all the items rated by u.

The neighborhood-based algorithm calculates the similarity between 2 users or items, and produces a prediction for the user past taking the weighted average of all the ratings. Similarity ciphering between items or users is an important part of this approach. Multiple measures, such as Pearson correlation and vector cosine based similarity are used for this.
The Pearson correlation similarity of two users x, y is defined as

where Ixy is the set of items rated by both user x and user y.
The cosine-based approach defines the cosine-similarity betwixt two users x and y as:[iv]

The user based peak-Northward recommendation algorithm uses a similarity-based vector model to identify the k well-nigh similar users to an active user. After the k about similar users are constitute, their respective user-item matrices are aggregated to identify the set of items to exist recommended. A popular method to find the similar users is the Locality-sensitive hashing, which implements the nearest neighbor mechanism in linear fourth dimension.
The advantages with this approach include: the explainability of the results, which is an important aspect of recommendation systems; like shooting fish in a barrel creation and utilize; easy facilitation of new data; content-independence of the items being recommended; good scaling with co-rated items.
There are too several disadvantages with this approach. Its performance decreases when data gets thin, which occurs ofttimes with web-related items. This hinders the scalability of this approach and creates bug with large datasets. Although it can efficiently handle new users because it relies on a information structure, calculation new items becomes more than complicated since that representation commonly relies on a specific vector space. Adding new items requires inclusion of the new item and the re-insertion of all the elements in the structure.
Model-based [edit]
In this approach, models are developed using unlike data mining, auto learning algorithms to predict users' rating of unrated items. There are many model-based CF algorithms. Bayesian networks, clustering models, latent semantic models such as singular value decomposition, probabilistic latent semantic analysis, multiple multiplicative factor, latent Dirichlet allocation and Markov decision process based models.[5]
Through this approach, dimensionality reduction methods are mostly being used as complementary technique to amend robustness and accuracy of memory-based approach. In this sense, methods similar singular value decomposition, main component analysis, known as latent cistron models, shrink user-particular matrix into a depression-dimensional representation in terms of latent factors. One advantage of using this approach is that instead of having a high dimensional matrix containing abundant number of missing values we will be dealing with a much smaller matrix in lower-dimensional space. A reduced presentation could be utilized for either user-based or particular-based neighborhood algorithms that are presented in the previous section. There are several advantages with this paradigm. It handles the sparsity of the original matrix better than memory based ones. Also comparison similarity on the resulting matrix is much more scalable especially in dealing with large sparse datasets.[vi]
Hybrid [edit]
A number of applications combine the memory-based and the model-based CF algorithms. These overcome the limitations of native CF approaches and improve prediction performance. Importantly, they overcome the CF issues such as sparsity and loss of data. However, they have increased complexity and are expensive to implement.[7] Commonly nearly commercial recommender systems are hybrid, for case, the Google news recommender system.[viii]
Deep-Learning [edit]
In recent years a number of neural and deep-learning techniques have been proposed. Some generalize traditional Matrix factorization algorithms via a not-linear neural compages,[9] or leverage new model types like Variational Autoencoders.[10] While deep learning has been applied to many different scenarios: context-aware, sequence-aware, social tagging etc. its real effectiveness when used in a unproblematic collaborative recommendation scenario has been put into question. A systematic analysis of publications applying deep learning or neural methods to the top-k recommendation trouble, published in pinnacle conferences (SIGIR, KDD, World wide web, RecSys), has shown that on average less than twoscore% of articles are reproducible, with equally little as fourteen% in some conferences. Overall the study identifies 18 articles, just vii of them could be reproduced and half-dozen of them could be outperformed past much older and simpler properly tuned baselines. The article too highlights a number of potential problems in today's research scholarship and calls for improved scientific practices in that area.[eleven] Similar issues have been spotted besides in sequence-aware recommender systems.[12]
Context-aware collaborative filtering [edit]
Many recommender systems only ignore other contextual data existing alongside user'due south rating in providing item recommendation.[thirteen] However, by pervasive availability of contextual information such as time, location, social data, and type of the device that user is using, it is becoming more important than ever for a successful recommender system to provide a context-sensitive recommendation. Co-ordinate to Charu Aggrawal, "Context-sensitive recommender systems tailor their recommendations to additional information that defines the specific situation under which recommendations are fabricated. This additional information is referred to every bit the context."[vi]
Taking contextual data into consideration, we will have additional dimension to the existing user-item rating matrix. As an instance, assume a music recommender system which provide different recommendations in respective to time of the twenty-four hour period. In this example, it is possible a user have different preferences for a music in different time of a day. Thus, instead of using user-detail matrix, we may use tensor of order iii (or higher for considering other contexts) to correspond context-sensitive users' preferences.[xiv] [15] [16]
In order to take advantage of collaborative filtering and particularly neighborhood-based methods, approaches tin can be extended from a two-dimensional rating matrix into a tensor of higher order[ citation needed ]. For this purpose, the approach is to find the most like/similar-minded users to a target user; one can extract and compute similarity of slices (due east.g. item-time matrix) respective to each user. Unlike the context-insensitive case for which similarity of two rating vectors are calculated, in the context-aware approaches, the similarity of rating matrices corresponding to each user is calculated by using Pearson coefficients.[half-dozen] After the most agreeing users are constitute, their corresponding ratings are aggregated to identify the set of items to be recommended to the target user.
The virtually important disadvantage of taking context into recommendation model is to exist able to deal with larger dataset that contains much more missing values in comparison to user-item rating matrix[ citation needed ]. Therefore, similar to matrix factorization methods, tensor factorization techniques can be used to reduce dimensionality of original data before using any neighborhood-based methods[ citation needed ].
[edit]
Unlike the traditional model of mainstream media, in which in that location are few editors who set guidelines, collaboratively filtered social media can have a very big number of editors, and content improves as the number of participants increases. Services like Reddit, YouTube, and Last.fm are typical examples of collaborative filtering based media.[17]
One scenario of collaborative filtering application is to recommend interesting or popular information equally judged by the community. As a typical instance, stories appear in the front end page of Reddit equally they are "voted upward" (rated positively) by the customs. As the community becomes larger and more than various, the promoted stories can better reflect the average interest of the community members.
Wikipedia is another application of collaborative filtering. Volunteers contribute to the encyclopedia by filtering out facts from falsehoods.[eighteen]
Another aspect of collaborative filtering systems is the ability to generate more than personalized recommendations by analyzing data from the past activity of a specific user, or the history of other users deemed to be of similar taste to a given user. These resource are used every bit user profiling and helps the site recommend content on a user-by-user basis. The more than a given user makes use of the organization, the ameliorate the recommendations become, as the system gains data to improve its model of that user.
Problems [edit]
A collaborative filtering arrangement does not necessarily succeed in automatically matching content to one's preferences. Unless the platform achieves unusually skilful diversity and independence of opinions, 1 point of view will always boss another in a detail community. As in the personalized recommendation scenario, the introduction of new users or new items tin crusade the cold start problem, as there will be insufficient data on these new entries for the collaborative filtering to piece of work accurately. In lodge to make appropriate recommendations for a new user, the system must outset acquire the user'south preferences by analysing past voting or rating activities. The collaborative filtering organisation requires a substantial wrong and sometimes users from backwoods countries and far abroad lands to rate a new item earlier that item can be recommended.
Challenges [edit]
Information sparsity [edit]
In practice, many commercial recommender systems are based on large datasets. As a result, the user-item matrix used for collaborative filtering could be extremely large and sparse, which brings nigh challenges in the operation of the recommendation.
I typical problem caused by the information sparsity is the cold start problem. As collaborative filtering methods recommend items based on users' past preferences, new users volition need to rate a sufficient number of items to enable the organization to capture their preferences accurately and thus provides reliable recommendations.
Similarly, new items as well have the same problem. When new items are added to the system, they need to be rated by a substantial number of users before they could be recommended to users who take similar tastes to the ones who rated them. The new item trouble does not touch content-based recommendations, considering the recommendation of an item is based on its discrete set of descriptive qualities rather than its ratings.
Scalability [edit]
As the numbers of users and items grow, traditional CF algorithms volition suffer serious scalability problems[ citation needed ]. For example, with tens of millions of customers and millions of items , a CF algorithm with the complexity of is already likewise large. As well, many systems need to react immediately to online requirements and make recommendations for all users regardless of their millions of users, with most computations happening in very large memory machines.[19]



Synonyms [edit]
Synonyms refers to the tendency of a number of the same or very similar items to have different names or entries. Most recommender systems are unable to discover this latent association and thus treat these products differently.
For example, the seemingly unlike items "children'due south flick" and "children'southward picture" are actually referring to the same detail. Indeed, the degree of variability in descriptive term usage is greater than ordinarily suspected.[ citation needed ] The prevalence of synonyms decreases the recommendation performance of CF systems. Topic Modeling (similar the Latent Dirichlet Allocation technique) could solve this by group different words belonging to the same topic.[ citation needed ]
Grayness sheep [edit]
Greyness sheep refers to the users whose opinions practice not consistently agree or disagree with whatever group of people and thus practise not benefit from collaborative filtering. Blackness sheep are a group whose idiosyncratic tastes make recommendations most impossible. Although this is a failure of the recommender system, non-electronic recommenders also take great problems in these cases, and then having black sheep is an acceptable failure.[ disputed ]
Shilling attacks [edit]
In a recommendation system where everyone can requite the ratings, people may give many positive ratings for their ain items and negative ratings for their competitors'. It is often necessary for the collaborative filtering systems to introduce precautions to discourage such manipulations.
Diverseness and the long tail [edit]
Collaborative filters are expected to increment diversity because they aid united states find new products. Some algorithms, even so, may unintentionally practice the opposite. Because collaborative filters recommend products based on past sales or ratings, they cannot usually recommend products with limited historical data. This tin create a rich-get-richer event for pop products, akin to positive feedback. This bias toward popularity tin can prevent what are otherwise better consumer-product matches. A Wharton written report details this miracle along with several ideas that may promote diversity and the "long tail."[xx] Several collaborative filtering algorithms have been developed to promote variety and the "long tail"[21] by recommending novel, unexpected,[22] and serendipitous items.[23]
Innovations [edit]
- New algorithms take been developed for CF as a result of the Netflix prize.
- Cross-Arrangement Collaborative Filtering where user profiles across multiple recommender systems are combined in a multitask style; this way, preference pattern sharing is achieved across models..[24]
- Robust collaborative filtering, where recommendation is stable towards efforts of manipulation. This enquiry area is notwithstanding active and not completely solved.[25]
Auxiliary information [edit]
User-particular matrix is a basic foundation of traditional collaborative filtering techniques, and it suffers from data sparsity problem (i.eastward. cold start). As a upshot, except for user-item matrix, researchers are trying to gather more auxiliary information to help boost recommendation performance and develop personalized recommender systems.[26] Generally, there are two pop auxiliary data: aspect information and interaction information. Attribute data describes a user's or an detail's properties. For case, user aspect might include general profile (eastward.g. gender and historic period) and social contacts (eastward.g. followers or friends in social networks); Item attribute means properties similar category, brand or content. In add-on, interaction information refers to the implicit information showing how users interplay with the item. Widely used interaction information contains tags, comments or reviews and browsing history etc. Auxiliary information plays a significant role in a diversity of aspects. Explicit social links, as a reliable representative of trust or friendship, is e'er employed in similarity calculation to find like persons who share involvement with the target user.[27] [28] The interaction-associated data - tags - is taken as a third dimension (in addition to user and particular) in advanced collaborative filtering to construct a 3-dimensional tensor construction for exploration of recommendation.[29]
See also [edit]
- Attending Profiling Mark-upwardly Language (APML)
- Common cold offset
- Collaborative model
- Collaborative search engine
- Collective intelligence
- Customer engagement
- Delegative Commonwealth, the aforementioned principle applied to voting rather than filtering
- Enterprise bookmarking
- Firefly (website), a defunct website which was based on collaborative filtering
- Filter bubble
- Page rank
- Preference elicitation
- Psychographic filtering
- Recommendation system
- Relevance (information retrieval)
- Reputation system
- Robust collaborative filtering
- Similarity search
- Slope I
- Social translucence
References [edit]
- ^ Francesco Ricci and Lior Rokach and Bracha Shapira, Introduction to Recommender Systems Handbook, Recommender Systems Handbook, Springer, 2011, pp. 1-35
- ^ a b Terveen, Loren; Hill, Will (2001). "Beyond Recommender Systems: Helping People Assist Each Other" (PDF). Addison-Wesley. p. 6. Retrieved 16 January 2012.
- ^ An integrated arroyo to Tv set & VOD Recommendations Archived vi June 2012 at the Wayback Machine
- ^ John S. Breese, David Heckerman, and Carl Kadie, Empirical Analysis of Predictive Algorithms for Collaborative Filtering, 1998 Archived 19 October 2013 at the Wayback Machine
- ^ Xiaoyuan Su, Taghi M. Khoshgoftaar, A survey of collaborative filtering techniques, Advances in Artificial Intelligence archive, 2009.
- ^ a b c Recommender Systems - The Textbook | Charu C. Aggarwal | Springer. Springer. 2016. ISBN9783319296579.
- ^ Ghazanfar, Mustansar Ali; Prügel-Bennett, Adam; Szedmak, Sandor (2012). "Kernel-Mapping Recommender system algorithms". Information Sciences. 208: 81–104. CiteSeerX10.1.1.701.7729. doi:x.1016/j.ins.2012.04.012.
- ^ Das, Abhinandan South.; Datar, Mayur; Garg, Ashutosh; Rajaram, Shyam (2007). "Google news personalization". Proceedings of the 16th international conference on World Wide Spider web - WWW '07. p. 271. doi:10.1145/1242572.1242610. ISBN9781595936547. S2CID 207163129.
- ^ He, Xiangnan; Liao, Lizi; Zhang, Hanwang; Nie, Liqiang; Hu, Xia; Chua, Tat-Seng (2017). "Neural Collaborative Filtering". Proceedings of the 26th International Briefing on World Wide Spider web. International World Wide Web Conferences Steering Commission: 173–182. arXiv:1708.05031. doi:10.1145/3038912.3052569. ISBN9781450349130. S2CID 13907106. Retrieved 16 October 2019.
- ^ Liang, Dawen; Krishnan, Rahul Yard.; Hoffman, Matthew D.; Jebara, Tony (2018). "Variational Autoencoders for Collaborative Filtering". Proceedings of the 2018 World Broad Spider web Conference. International World Wide Web Conferences Steering Committee: 689–698. arXiv:1802.05814. doi:10.1145/3178876.3186150. ISBN9781450356398.
- ^ Ferrari Dacrema, Maurizio; Cremonesi, Paolo; Jannach, Dietmar (2019). "Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches". Proceedings of the 13th ACM Briefing on Recommender Systems. ACM: 101–109. arXiv:1907.06902. doi:10.1145/3298689.3347058. hdl:11311/1108996. ISBN9781450362436. S2CID 196831663. Retrieved 16 October 2019.
- ^ Ludewig, Malte; Mauro, Noemi; Latifi, Sara; Jannach, Dietmar (2019). "Operation Comparison of Neural and Not-neural Approaches to Session-based Recommendation". Proceedings of the 13th ACM Briefing on Recommender Systems. ACM: 462–466. doi:10.1145/3298689.3347041. ISBN9781450362436 . Retrieved 16 Oct 2019.
- ^ Adomavicius, Gediminas; Tuzhilin, Alexander (1 January 2015). Ricci, Francesco; Rokach, Lior; Shapira, Bracha (eds.). Recommender Systems Handbook. Springer Us. pp. 191–226. doi:x.1007/978-1-4899-7637-6_6. ISBN9781489976369.
- ^ Bi, Xuan; Qu, Annie; Shen, Xiaotong (2018). "Multilayer tensor factorization with applications to recommender systems". Annals of Statistics. 46 (6B): 3303–3333. arXiv:1711.01598. doi:10.1214/17-AOS1659. S2CID 13677707.
- ^ Zhang, Yanqing; Bi, Xuan; Tang, Niansheng; Qu, Annie (2020). "Dynamic tensor recommender systems". arXiv:2003.05568v1 [stat.ME].
- ^ Bi, Xuan; Tang, Xiwei; Yuan, Yubai; Zhang, Yanqing; Qu, Annie (2021). "Tensors in Statistics". Annual Review of Statistics and Its Awarding. viii (i): annurev. Bibcode:2021AnRSA...842720B. doi:ten.1146/annurev-statistics-042720-020816. S2CID 224956567.
- ^ Collaborative Filtering: Lifeblood of The Social Web Archived 22 April 2012 at the Wayback Machine
- ^ Gleick, James (2012). The data : a history, a theory, a flood (1st Vintage books ed., 2012 ed.). New York: Vintage Books. p. 410. ISBN978-1-4000-9623-7. OCLC 745979816.
- ^ Pankaj Gupta, Ashish Goel, Jimmy Lin, Aneesh Sharma, Dong Wang, and Reza Bosagh Zadeh WTF: The who-to-follow arrangement at Twitter, Proceedings of the 22nd international conference on Www
- ^ Fleder, Daniel; Hosanagar, Kartik (May 2009). "Blockbuster Culture's Adjacent Rise or Autumn: The Impact of Recommender Systems on Sales Diversity". Management Science. 55 (5): 697–712. doi:x.1287/mnsc.1080.0974. SSRN 955984.
- ^ Castells, Pablo; Hurley, Neil J.; Vargas, Saúl (2015). "Novelty and Multifariousness in Recommender Systems". In Ricci, Francesco; Rokach, Lior; Shapira, Bracha (eds.). Recommender Systems Handbook (ii ed.). Springer US. pp. 881–918. doi:x.1007/978-1-4899-7637-6_26. ISBN978-1-4899-7637-6.
- ^ Adamopoulos, Panagiotis; Tuzhilin, Alexander (January 2015). "On Unexpectedness in Recommender Systems: Or How to Amend Look the Unexpected". ACM Transactions on Intelligent Systems and Technology. five (4): 1–32. doi:ten.1145/2559952. S2CID 15282396.
- ^ Adamopoulos, Panagiotis (October 2013). Beyond rating prediction accuracy: on new perspectives in recommender systems. Proceedings of the seventh ACM Conference on Recommender Systems. pp. 459–462. doi:10.1145/2507157.2508073. ISBN9781450324090. S2CID 1526264.
- ^ Chatzis, Sotirios (October 2013). "Nonparametric Bayesian multitask collaborative filtering". CIKM '13: Proceedings of the 22nd ACM international briefing on Data & Knowledge Management. Portal.acm.org. pp. 2149–2158. doi:10.1145/2505515.2505517. ISBN9781450322638. S2CID 10515301.
- ^ Mehta, Bhaskar; Hofmann, Thomas; Nejdl, Wolfgang (xix Oct 2007). Proceedings of the 2007 ACM briefing on Recommender systems - Rec Sys '07. Portal.acm.org. p. 49. CiteSeerXx.i.1.695.1712. doi:10.1145/1297231.1297240. ISBN9781595937308. S2CID 5640125.
- ^ Shi, Yue; Larson, Martha; Hanjalic, Alan (2014). "Collaborative filtering across the user-item matrix: A survey of the state of the art and time to come challenges". ACM Computing Surveys. 47: 1–45. doi:10.1145/2556270. S2CID 5493334.
- ^ Massa, Paolo; Avesani, Paolo (2009). Computing with social trust. London: Springer. pp. 259–285.
- ^ Groh Georg; Ehmig Christian. Recommendations in taste related domains: collaborative filtering vs. social filtering. Proceedings of the 2007 international ACM conference on Supporting group work. pp. 127–136. CiteSeerX10.i.1.165.3679.
- ^ Symeonidis, Panagiotis; Nanopoulos, Alexandros; Manolopoulos, Yannis (2008). Tag recommendations based on tensor dimensionality reduction. Proceedings of the 2008 ACM Briefing on Recommender Systems. pp. 43–50. CiteSeerX10.1.i.217.1437. doi:10.1145/1454008.1454017. ISBN9781605580937. S2CID 17911131.
External links [edit]
- Beyond Recommender Systems: Helping People Help Each Other, page 12, 2001
- Recommender Systems. Prem Melville and Vikas Sindhwani. In Encyclopedia of Machine Learning, Claude Sammut and Geoffrey Webb (Eds), Springer, 2010.
- Recommender Systems in industrial contexts - PHD thesis (2012) including a comprehensive overview of many collaborative recommender systems
- Toward the adjacent generation of recommender systems: a survey of the land-of-the-art and possible extensions [ dead link ] . Adomavicius, K. and Tuzhilin, A. IEEE Transactions on Knowledge and Information Applied science 06.2005
- Evaluating collaborative filtering recommender systems (DOI: 10.1145/963770.963772)
- GroupLens research papers.
- Content-Additional Collaborative Filtering for Improved Recommendations. Prem Melville, Raymond J. Mooney, and Ramadass Nagarajan. Proceedings of the Eighteenth National Conference on Bogus Intelligence (AAAI-2002), pp. 187–192, Edmonton, Canada, July 2002.
- A collection of past and present "data filtering" projects (including collaborative filtering) at MIT Media Lab
- Eigentaste: A Constant Time Collaborative Filtering Algorithm. Ken Goldberg, Theresa Roeder, Dhruv Gupta, and Chris Perkins. Information Retrieval, iv(2), 133-151. July 2001.
- A Survey of Collaborative Filtering Techniques Su, Xiaoyuan and Khoshgortaar, Taghi. M
- Google News Personalization: Scalable Online Collaborative Filtering Abhinandan Das, Mayur Datar, Ashutosh Garg, and Shyam Rajaram. International Globe Wide Web Conference, Proceedings of the 16th international conference on World Wide Spider web
- Factor in the Neighbors: Scalable and Accurate Collaborative Filtering Yehuda Koren, Transactions on Knowledge Discovery from Data (TKDD) (2009)
- Rating Prediction Using Collaborative Filtering
- Recommender Systems
- Berkeley Collaborative Filtering

How Does Collaborative Filtering Work,
Source: https://en.wikipedia.org/wiki/Collaborative_filtering
Posted by: perrywhearommens.blogspot.com
0 Response to "How Does Collaborative Filtering Work"
Post a Comment